Sintesi granulare 2 – dalla teoria alla pratica
Nella scorsa puntata abbiamo esplorato la storia della sintesi granulare, partendo dalle intuizioni prettamente “scientifiche” di Dannis Gabor e passando per l’elaborazione “musicale” di Iannis Xenakis, fino ad arrivare alle soglie dei giorni nostri con la possibilità di sperimentare in lungo e in largo le molteplici sonorità che questa tecnica offre, magari semplicemente scaricando un paio di programmini e giocando a muovere i parametri col mouse. Già, ma quali parametri muovere?
Di Francesco Bernardini
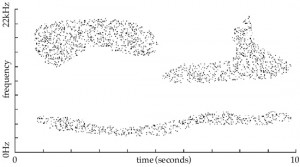
In questa puntata ci addentreremo un po’ più in profondità nella questione tecnica e vedremo come la sintesi granulare – come abbiamo già avuto modo di affermare – non sia tanto un “effetto” (anche se serve pure per effettare e processare il suono), quanto – molto più drasticamente – un modo diverso di concepire la modellazione del suono stesso.
Partiamo dai dinosauri
Uno degli utilizzi più immediati della sintesi granulare applicata ad un segnale è la modificazione della sua frequenza (pitch) attuata senza alterazione della sua durata. In pratica, il celeberrimo pitch shifting: canto una nota nel microfono e la macchina me la ripropone una quinta sopra: la durata del campione rimane esattamente la stessa, ma la sua frequenza di playback è variata. Addirittura, col mio piccolo Lexicon posso ottenere questo effetto in real time, trasformando la mia vecchia Yamaha RGX in un basso a sei corde (sono già stato all’Ufficio Bestialità Chitarristiche e ho già pagato il bollo di due vergate sui dorsi delle mani per questa, grazie…).
Tutto ciò si fa tramite la sintesi granulare. Per avere un quadro più chiaro della faccenda faremo un parallelo tra la primissima applicazione di questa tecnica – guarda caso, proprio riguardo al pitch shifting – ed un celeberrimo esempio scritto da Johannes Kreidler e tratto da “Programming electronic music in Puredata” (http://www.pd-tutorial.com/).
Impostiamo il flusso canalizzatore, forniamo 1,21 gigawatt di potenza e torniamo al 1946: Dannis Gabor progetta un complesso sistema di granularizzazione del suono che è sostanzialmente un pitch shifter basato su una coppia costituita da emettitore di impulsi luminosi (una lampadina posta dietro un nastro rotante perforato) sincronizzato ad una fotocellula. Tra i due, un nastro ottico da 16mm sul quale era impresso il segnale sonoro, che veniva “finestrato” tramite un rettangolo oscurato ai margini (per ricreare un inviluppo “a campana” – o gaussiano). L’immagine l’abbiamo già vista:
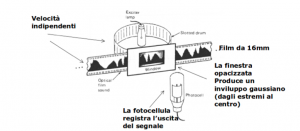
Ora, è il momento di qualche spiegazione: durante la rotazione del tamburo, le fessure fanno in modo che la luce colpisca il nastro in una sequenza di “flash” di frequenza controllata (e determinata ovviamente dalla velocità di rotazione del tamburo stesso): questa serie di “istantanee” attraversano il nastro da 16mm su cui è “impresso” il suono e la cornice oscurata agli estremi (per ricavare una forma di inviluppo adeguata ad eliminare i click che verrebbero generati da un attacco/rilascio di ampiezza maggiore di zero) per venire infine catturati dalla fotocellula. I singoli “flash” sonori costituiscono qui i “grani”, ovvero le particelle elementari in cui il segnale audio viene scomposto, in modo simile a quello che accade quando un segnale video viene catturato da una cinepresa e impresso in singoli fotogrammi sulla pellicola di un film.
Ora, per avere un quadro migliore della faccenda, affrontiamo questo stesso identico problema razionalizzandolo in termini astratti e riproponendolo tramite un linguaggio di programmazione visuale.
Mettiamo in pratica Dannis Gabor
Useremo qui un arnese chiamato Puredata, ovvero una sorta di “linguaggio” di programmazione orientato alla manipolazione audiovisiva, messo a punto da un tizio chiamato Miller Pukette. Da Puredata deriva direttamente il celebre ambiente MAX: rilasciato in licenza open source, Puredata è attualmente concepito come una sorta di “sandbox” lasciata al “coding” libero, un “pozzo” da cui prendere spunti per i futuri sviluppi di MAX e soci. In pratica, si tratta di un ambiente di programmazione ad alto livello (il che in informatichese sta a significare: si fa tutto col mouse e si impara facendo) disponibile in forma assolutamente gratuita e libera da ogni forma di vincolo licenziale (ergo: possiamo fare i dischi senza che nessuno venga a reclamare diritti) che ci consente – con una curva di apprendimento relativamente corta – di giocare con il suono e di manipolare le note così come faremmo con un sistema modulare “totale”, ma senza lasciarci la pelle del gomito a suon di firmare cambiali. Ho scelto questo ambiente per gli esempi perché è disponibile per ogni piattaforma (anche per cellulare) e chiunque abbia interesse può installarlo ed utilizzarlo liberamente; la “sintassi” degli esempi è tuttavia riproducibile senza praticamente alcuno sforzo su ambienti proprietari come MAX stesso (in cui cambiano solo pochi nomi di oggetti), Reaktor e simili. Un altro ambiente totalmente open source (ergo gratis e multipiattaforma) che consente di sperimentare le patch presentate lavorando con un sistema punta e clicca – decisamente orientato agli utenti di sintetizzatori modulari “old school” – è il celebre AMS. Le “patch” di Puredata possono inoltre fungere egregiamente come sinossi di sviluppo per una eventuale codificazione in linguaggi di livello più basso (in informatichese questo significa “sporcarsi le mani col codice” e magari “compilare roba”, ergo curva di apprendimento decisamente più ripida) quali SuperCollider, Csound, Faust e simili. Ragion per cui, se qualcuno ha intenzione di lanciare l’ennesimo VST che fa grainsynth in un mercato già stra-saturo di soluzioni, qui ha tutti gli strumenti per progettarlo. E, già che siamo in tema di rimandi esterni, per completezza cito qui il “Paul’s Extreme Sound Stretch”, un programma che consente di “allungare” il suono in modo così estremo da arrivare al punto di generare favoleggianti soundscapes di decine di munuti a partire da pochi secondi di chessò – Burzum? – Da provare.
L’esempio di Kreidler
Immaginiamo di voler modificare il pitch di un campione audio: è un dato palese che, volendo aumentare la sua frequenza, potremmo semplicemente aumentare la sua velocità di emissione. Ci ritroveremmo così con un segnale shiftato, sì, ma anche più breve in durata: il “nastro” è stato riavvolto a velocità maggiore e naturalmente è “finito” prima. Al contrario, se volessimo diminuire il pitch del campione originario, potremmo fare play ad una frequenza minore di quella di campionamento – ma, in questo caso, otterremmo inevitabilmente un sample di durata maggiore di quello originario. Tutto questo renderebbe inutilizzabile la modificazione del pitch in presenza, per esempio, di una ritmica precisa da dover seguire. Come bypassare il problema in modo pratico?
Poniamo che questa linea rappresenti il nostro campione e la sua inclinazione determini la velocità di playback:
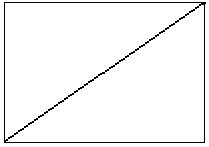
Alzando la velocità di riproduzione determiniamo un aumento dell’inclinazione della linea, che di conseguenza “termina” prima del tempo…
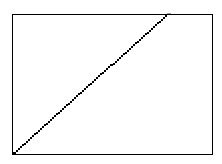
In sostanza, con la sintesi granulare, otteniamo invece questo tipo di comportamento:
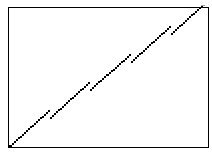
Abbiamo in pratica “spezzettato” la nostra linea e ricomposto il segnale mettendo “in fila” i vari pezzetti alla velocità di playback che avevamo scelto. Questi “pezzetti” di segnale sono – l’avrete capito – i “grani” audio su cui andremo a lavorare.
Questo esempio è molto semplicistico, daccordo, e non tiene in considerazione – tanto per dire – la discontinuità che abbiamo creato nella linea un tempo integra… ma andiamo per gradi ed iniziamo a rompere il ghiaccio con Puredata e i suoi cavetti (consigliati dall’Associazione Italiana Medici Oculisti).
Per cominciare, definiamo il modo in cui verrà “suonato” ogni singolo grano audio:
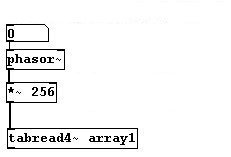
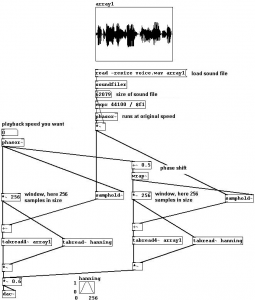
Iniziando dall’alto: il primo “quadratino” è un oggetto di input (lo si riconosce dal bordo tagliato come quello di un assegno trassato da una banca). In pratica, cliccando qui l’utente potrà definire un valore nella casellina che mostra lo 0 iniziale. Questo valore viene passato al quadratino sottostante, che invece è un oggetto ben preciso: “phasor~” (il ~ in pd sta sempre ad indicare che c’è di mezzo un segnale audio) è un semplice oscillatore a dente di sega che restituisce una rampa di valori da 0a 1. La velocità con cui phasor compie un ciclo da 0 a 1 è determinata dal valore in ingresso, dove 1 sta per 1 hertz. La rampa di valori in uscita dall’oscillatore viene moltiplicata per 256: questo valore rappresenta l’ampiezza della nostra “finestra” audio, espressa brutalmente in numero di sample. Ok, abbiamo definito la lunghezza del nostro “grano”: l’ultimo quadratino prende questa ampiezza e legge la finestra corrispondente da un campione audio chiamato “array1”.
In questo modo, però, non facciamo altro che leggere solo il primo grano del campione e basta: per fare in modo di ripetere l’operazione ogni volta che un grano precedente viene “letto” dalla nostra “testina” virtuale, utilizzeremo un oggetto un tantino più complesso, che è sostanzialmente la versione di Puredata del “Sample&Hold”. “Samphold~”, per l’appunto, è un quadratino che accetta due input: in quello di sinistra il segnale, in quello di destra un secondo segnale, ma di controllo. Il suo comportamento è il seguente: fin tanto che il segnale di destra è discendente (ovvero fin quando il valore che restituisce è sempre inferiore di quello restituito in precedenza) il segnale di sinistra viene fatto passare. Lo so, detto così sembra completamente insensato, ma tutto prende forma non appena si prova a far passare sul segnale di destra di “samphold~” una qualche forma d’onda coerente (tipo quella buttata fuori da un oscillatore del quale possiamo controllare la frequenza): usando a questo scopo lo stesso “phasor~” che utilizzavamo prima per la lettura del singolo campione, possiamo sincronizzare quest’ultima in modo da “ricominciare” ogni volta che il ciclo di playback del grano giunge a termine, indipendentemente dalla frequenza di lettura. A questo punto, è sufficiente aggiungere alla patch un valore di offset che ci consenta di “muovere in avanti” la “testina”… ma mi rendo conto che, detto così, tutto questo possa risultare confuso; quindi mano al mouse e colleghiamo i cavetti più o meno così (sempre con i complimenti dell’AIMO):
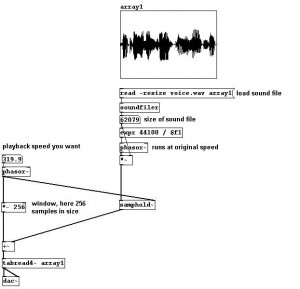
Niente paura: partendo dall’alto, la prima cornice con dentro quella macchia nera è il nostro campione (array1). Subito sotto, come dice l’etichetta, la prima riga manda a quella immediatamente successiva un comando: leggi il file “voice.wav” e mettilo in array1 ridimensionandolo automaticamente (ergo “array1” sarà lungo esattamente il numero di sample che costituiscono il file “voice.wav”): questa dimensione viene buttata nel quadratino che riporta “62079” (è messo lì solo per mostrare il valore a video) e passa poi tramite una espressione (un oggetto di pd dedicato alla manipolazione dei dati) che divide 44100 (ovvero il sample-rate a cui è registrato “voice1.wav”) per la sua lunghezza totale in sample (ovvero 62079 sample). Il rapporto così ottenuto è la frequenza con cui “phasor~” compirà il suo ciclo, leggendo quindi il campione alla sua frequenza originale. Il segnale viene mandato nell’input di sinistra di “samphold~”: in quello di destra, abbiamo invece l’output di un secondo “phasor~”, ovvero quello che abbiamo utilizzato in precedenza per la lettura del singolo grano: a sincro con la lettura della finestra di 256 sample “tratti” dal campione “array1” avremo l’avanzamento dell’indice di lettura tratto dall’output di “samphold~”, e via via addizionato alla finestra generata dal secondo “phasor~” (la “testina” si muove in avanti). Il dato viene infine passato a “tabread4~”, che legge dunque un campione di 256 sample per volta, alla frequenza indicata nel quadratino in alto (quello che riporta “319.9”). Ok, ok, tornate pure a sedere, tanto abbiamo fatto sbarrare le porte dall’esterno. Calmatevi, e abbiate fede: non è importante capire perfettamente come funziona tutto questo in puredata (per approfondire, si può iniziare da qualsiasi tutorial presente su internet) , quanto tenere a mente il parallelismo con la “macchina” di Gabor: i due “phasor~” sono i due rulli (quello del tamburo perforato che scatta le “fotografie” e quello che muove il nastro su cui è “impresso” l’audio), mentre i 256 sample rappresentano la “lunghezza” della finestra audio che costituirà il nostro “grano” sonoro.
In questo esempio, tuttavia, non abbiamo fatto altro che prendere il suono, spezzettarlo e riprodurre i singoli pezzetti uno dietro l’altro ad una frequenza di playback indipendente da quella di origine: in questo modo possiamo mantenere la continuità di percezione sufficiente a ricreare l’idea di un suono “intero” solo lavorando entro margini molto ristretti di intervento. Infatti, non appena alziamo un po’ troppo la frequenza di playback dei singoli grani, otteniamo subito un “click” che deriva dal fatto che un singolo grano è “terminato” troppo in fretta, mentre se abbassiamo la frequenza rispetto a quella originaria di lettura del campione, il grano “non farà in tempo” a terminare il playback prima che il successivo attacchi. Inoltre, la mancanza di una qualsivoglia forma d’inviluppo rende il tutto un macello di cick e ciack.
Iniziamo a raffinare il sistema introducendo la “finestra oscurata”, ovvero l’inviluppo:
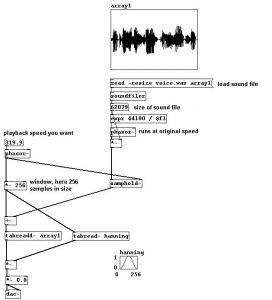
Eccola là in fondo: è una curva gaussiana che va da 0 a 1 in altezza e da 0 a 255 in lunghezza. A valle del circuito, prima dell’uscita audio (che l’avrete capito, è l’oggetto “dac~” con i suoi due ingressi L/R), è inserito un moltiplicatore audio: questo oggetto effettua una moltiplicazione tra il valore in ingresso a sinistra (il grano letto in modo “raw” e privo d’inviluppo) e quello a destra (la nostra finestra). I due indici sono sincronizzati dalla finestra stessa (il moltiplicatore per 256 posto prima dell’offset): in questo modo la finestra di hanning viene sovrapposta all’ampiezza del grano, generando un inviluppo che elimina i click di attacco/rilascio.
Resta un problema: messo giù così, il sistema può fungere fintanto che lo usiamo per abbassare la frequenza di un segnale, perché comunque la lunghezza di ogni singolo grano sarà maggiore della finestra di sampling, e grazie all’inviluppo potremmo riuscire a “riempire” la finestra stessa senza creare discontinuità di segnale. Ma non appena proviamo a ad avvicinarci alla frequenza originale, o addirittura ad aumentarla, avremo dei grani troppo corti per “riempire” quei 256 sample necessari alla finestrazione audio. Come fare? Brutalmente, potremmo fare un bel copia/incolla di tutta la faccenda e creare un secondo segnale che sia esattamente come il primo, ma spostato di fase della metà:
Ora possiamo giocare a modificare il pitch di un campione sia aumentando che diminuendo la sua frequenza di origine, senza alterare la sua durata. Ma se volessimo invece alterare la durata senza modificare il pitch? Basta aggiungere un controllo alla frequenza del “phasor~” che regola la velocità di lettura (finora, ricordate, è stata rigorosamente quella originaria, ricavata con quella semplice divisione):
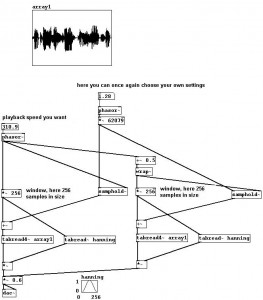
A questo punto abbiamo la possibilità di variare indipendentemente pitch e durata di un campione audio (entro, ovviamente, certi limiti) semplicemente cambiando la frequenza di lettura delle due “testine”. Questo è un semplice spunto da cui si può partire per progettare cose molto più complesse: tanto per cominciare, usando un paio di oggetti “delay~” (che – guarda caso – fungono da delay) al posto del campione audio potremmo manipolare il pitch di un segnale in real time (utilizzando il delay per “catturare” ogni grano). Inoltre, sarebbe interessante poter variare l’ampiezza della finestra di sampling, nonché la forma dell’inviluppo (l’esempio completo è disponibile qui: http://www.pd-tutorial.com/english/ch03s07.html).
Fatto questo, potremmo spingerci oltre: perché fermarci a sole due “voci”, che rappresentano il “minimo sindacale” per fare grainsynth? Potremmo sperimentare con quattro, sedici, trentadue, diecimila. E potremmo parametrizzarle in modo indipendente o linkato (una potrebbe riprodurre alla frequenza doppia dell’altra, per esempio). Alcune potrebbero produrre flussi audio continui, altre forme di natura pulviscolare, magari “sparando” i grani opportunamente inviluppati e spalmati sul panorama stereo. Potremmo quindi voler dotare ogni voce anche di un controllo pan, e, perché no, magari anche di un LFO per modulare qualche variabile del sistema, etc… etc…
Credo sia sufficientemente chiaro come da un singolo campione audio, o da una sola pernacchia nel microfono, tramite la sintesi granulare sia possibile ottenere una varietà di effetti e soluzioni armoniche che raramente si ottengono con altre forme di sintesi classica. Non a caso, sebbene non abbia praticamente rappresentati “storici” legati ad un qualche modello di sintetizzatore (come accade per la sintesi sottrattiva con Moog, Korg e soci), la sintesi granulare, con l’avanzamento inesorabile (e triste) del digitale, si è infilata praticamente dappertutto. Vedremo, in una sorta di chiacchierata finale sull’argomento, come – in sostanza – anche il concetto stesso di conversione analogico/digitale sia fondata sulla finestrazione del segnale audio, così come l’analisi delle trasformate di Fourier, che ci consente di lavorare con un qualsiasi plugin che fa da equalizzatore.
Nella prossima puntata, finalmente, sentiremo anche qualcosa che non sia un noioso pitch shifter e faremo il punto sulle più comuni tecniche applicate alla e con la grainsynth.
A presto!
Tags: Puredata, Sintesi granulare
Trackback from your site.
Comments (11)
frabb
| #
c’è un piccolo refuso nel pezzo (sicuramente dovuto al casino che ho fatto io mandandolo in formati poco amici dell’editing web): tra la prima immagine “con la riga” (velocità del campione normale) e la seconda (velocità del campione aumentata), c’era questo pezzetto di testo:

“Alzando la velocità di riproduzione determiniamo un aumento dell’inclinazione della linea, che di conseguenza “termina” prima del tempo”
Che spiegava per l’appunto il secondo disegnino
Se qualcuno ha richieste in particolare per la terza parte, la sto preparando in questi giorni
ciao !
Reply
frabb
| #
ah, e quando si parla del phasor, ovviamente il range è DA 0 A 1 e non il contrario – ergo: dovrei abbassare il volume degli slayer mentre rileggo gli articoli
Reply
Enrico Cosimi
| #
corretto!!! 😀
Reply
Efrem
| #
Ciao,
io volevo chiedervi se avevate postato qualche articolo o tutorial che spiega della fase del suono. Ho notato che anche alcuni Vsti hanno anche questo comando (correggetemi se sbaglio). MI è capitato di fare qualche musichetta anche alcuni giorni fa e ho notato che la forma d’onda non era bilanciata sulla linea per ogni canale ma, tendeva a sporgere più verso il basso, questo indica errori di fase? Forse è un argomento lungo che va spiegato con calma ma volevo chiedervi se avevate scritto qualcosa in merito e se ci sono differenze tra sbagliare la fase registrando in digitale con Vsti e registrare con strumenti musicali analogici..Se non erro, l’errore di fase che può capitare più spesso lo si trova quando si registra con i microfoni.. Avete magari dei link che spiegano come lavorare correttamente con la fase in tutti e due i casi ? Grazie
Reply
Silvano Audisio
| #
l’argomento è abbastanza vasto per essere spiegato in poche riche… per cui provo a dare il mio parere da due soldi sperando di non dire stupidaggini: se il suono “sporge verso il basso”, cioè è più ampio nel quadrante negativo, non è un problema che ha a che fare con la fase, ma semmai con un DC offset… oppure potrebbe essere la caratteristica di quella particolare forma d’onda (non bisogna comunque fidarsi troppo della visualizzazione di alcuni editor fintanto che non si raggiunge un livello di zoom sufficiente a vederne il dettaglio). Il problema del DC offset può essere risolto facilmente con editor audio (Audacity, Wavelab, Soundforge…) con comandi dedicati a questo aspetto.
La fase invece riguarda piuttosto lo spostamento sull’asse X (dominio del tempo e non dell’ampiezza) e può diventare problematica quando due segnali diversi (due microfoni oppure canale sx e dx…) non sono in una corretta relazione di fase(una delle due onde è spostata in avanti rispetto all’altra), in questo caso le ampiezze dei due segnali potrebbero sottrarsi invece che sommarsi oppure dare (nel caso di un segnale stereo) strani effetti di spazializzazione poco naturale nel panorama stereofonico. E’ facile riscontrare questo problema in una ripresa di una singola sorgente con due microfoni posizionati a distanze differenti… nel caso di plugin potrebbe essere generato da alcuni effetti che lavorano nel dominio del tempo (riverberi, delay, effetti di spazializzazione…) se questi venissero settati in modo particolarmente problematico. In molti casi il problema della fase si può risolvere (o attenuare) con apposti delay molto corti che riescono a lavorare nel dominio di pochi samples o pochissimi millisec. (es: Sample delay di logic). spero di non aver fatto confusione.
Reply
frabb
| #
no, non hai fatto confusione, casomai sei entrato fin troppo nello specifico
La fase di un segnale stereofonico rappresenta in buona sostanza la differenza tra il segnale detro e quello sinistro. Si parla infatti di “correlazione di fase”, che indica “quanto” i due segnali sono “correlati” tra loro nell’immagine stereofonica. Come hai spiegato benissimo, un esempio classico è dato quando riprendiamo la stessa sorgente con due microfoni posti a distanze differenti: se non correggiamo il segnale potremmo trovarci con un suono “schiacciato” invece che correttamente spazializzato, in quanto di due sengali “si picchiano” tra loro quando vengono percepiti dall’orecchio. Un altro esempio – al contrario – può essere quello di voler “aprire” un suono – magari registrato direttamente in digitale – che ci arriva troppo “sparato in faccia” (un esempio classico sono le ritmiche nella musica elettronica): in questo caso si può giocare con la correlazione di fase per creare quello “sfasamento” necessario ad “allontanare” il suono dal naso dell’ascoltatore. Non vedo come questo possa entrarci con la sintesi granulare, ma l’argomento è interessantissimo e poco “battuto” in ambito di tutorial….
Reply
Efrem
| #
Si in effetti non ha a che fare con sintesi la granulare.. E se si inserisse un forum su questo sito per parlare di vari argomenti ?
Reply
Enrico Cosimi
| #
il template WP non permette la costituzione di forum…
Reply
frabb
| #
dov’è il problema? se il sito è hostato su una farm tipo wordpress.org si può “mettere su” un forum da un’altra parte e linkarlo, le credenziali di accesso possono essere condivise (wp è compatibile con il 99% dei bb in giro)… se invece l’host è proprietario (c’è uno spazio ftp in cui uploadare la roba in pratica) basta installare un forum in una directory qualunque del server e linkarlo a wp (stesso discorso di prima).
CIao
Reply
Enrico Cosimi
| #
per ora, il forum ha una priorità molto bassa…
Reply
Efrem
| #
Ok, grazie
Reply