Sintesi granulare 3 – Facciamo un po’ di rumore
Nelle precedenti puntate dedicate alla grainsynth abbiamo avuto modo di compiere un breve excursus storico/tecnico di questa particolare forma di sintesi, partendo dalle origini delle teorie di Dannis Gabor per poi passare al lato pratico della faccenda, e programmando un essenziale pitch-shifter, basato per l’appunto sulla granulazione audio, con il quale eravamo già in grado di modificare durata e frequenza di un campione mantenendo indipendenti tra loro questi due parametri (ovvero modificando l’uno senza variare l’altro).
Di Francesco Bernardini

Questa volta cercheremo di mettere in pratica quanto finora esposto nel tentativo di estrapolarne una qualche forma di musicalità, e tentando dunque di utilizzare la sintesi granulare come un vero e proprio “strumento” invece che come mero “effetto speciale audio”.
Assimilati i meccanismi e i concetti di base (grano di suono, inviluppo-per-grano, cloud acustico etc… etc…), passiamo ora ad utilizzare un granularizzatore vero e proprio, in grado di processare in tempo reale un segnale audio, e munito di qualche parametro un tantino più avanzato dei semplici controlli di pitch e durata del campione. Restando sempre, per praticità, in ambito Pure Data, l’oggetto che ho scelto per questo articolo si chiama “granulator~” e fa parte della libreria “mtl”, realizzata da David Golightly, e presente di default nell’installazione della versione “extended” di Pure Data (una pacchettizzazione che semplifica molto il lavoro mettendo già a disposizione del programmatore tutta una serie di librerie e oggetti di uso comune, assenti nella versione “nuda e pura”, altrimenti detta “vanilla”, di pd). Eccolo qui:
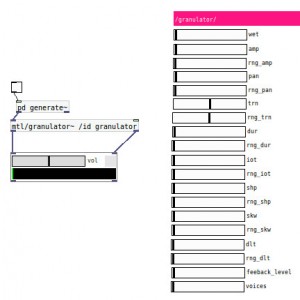
Il nostro “granulator~” ha sostanzialmente un input audio (puredata li chiama “inlet”) e uno “di controllo”, che invece accetta dati, il quale può essere impiegato per recepire parametri da altre patches, controller etc… (un’architettura piuttosto comune in pd/MAX). Noi ci limiteremo in questi esempi ad utilizzare un set di comodi fader orizzontali già belli e preconfigurati, ma ovviamente tutto è scriptabile e patchabile come meglio si crede (assolto Bollo all’Accademia Della Crusca). I due output (“outlet”) audio costituiscono l’uscita stereo del granularizzatore.
Passiamo ora ad esaminare nel dettaglio i singoli parametri che questa scatoletta ci mette a disposizione. In ordine, a partire dall’alto:
- Wet è, per l’appunto, un normalissimo controller di tipo “wet/dry” che ci consente di bilanciare la quantità di segnale processato e di segnale “pulito”. Quando è spostato completamente a destra, sentiremo solo il segnale processato, mentre quando sta a sinistra il granularizzatore sarà sostanzialmente bypassato in toto.
- Amp è il controllo di volume dei singoli grani, ovvero del segnale processato. Potrebbe non avere molto senso avendo già il Wet, ma acquisisce un suo significato nel momento in cui decidiamo di spostare dallo zero il fader successivo;
- Rng-Amp, infatti, ci consente di randomizzare il parametro precedente in un determinato range positivo-negativo rispetto al valore di centro settato dal fader superiore: a destra la randomizzazione sarà totale, mentre settandolo al 10%, per esempio, avremo un range di valori randomici che variano di più o meno il 10% rispetto al valore del fader Amp. Attenzione: questo controllo ed il precedente sono riferiti ad ogni singolo grano, ovvero varierà in modo indipendente il volume di ogni grano, così che a settaggi “ampi” avremo per esempio un grano a volume bassissimo ed il successivo sparato a palla…
- Pan ci consente di spostare a destra e a sinistra il grano audio nel panorama stereo. Anche lui è seguito dal suo bel:
- Rng-Pan, che agendo esattamente come Rng-Amp randomizza la posizione L/R sempre con riferimento al singolo grano audio.
- Trn è il nostro bel pitch-shifter che ci consente di controllare la frequenza a cui verrà riprodotto il grano, espressa in centesimi di tono. In posizione centrale il grano viene riprodotto alla sua frequenza originale, mentre spostando il fader a destra o a sinistra si ottiene un tono più acuto o più grave.
- Rng-Trn, ormai l’avrete capito, agisce sul precedente parametro esattamente come Rng-Amp e Rng-Pan. Anzi, possiamo tranquillamente saltare la descrizione di tutti gli altri fader di tipo Rng-qualcosa perché il loro funzionamento è sempre lo stesso.
- Dur indica la durata del grano, da 3 millisecondi per grano a 8 secondi. Perché proprio otto secondi? Perchè secondo qualcuno – gentaglia tipo Karlheinz Stockhausen – “otto secondi” è un “numero magico” nella musica tanto quanto i fatidici “20 millisecondi” a cui l’orecchio umano cessa, per esempio, di percepire un “click” quando un volume viene variato in realtime. Otto secondi sarebbero più o meno il “limite massimo” di percezione acustica della continuità ritmica: detta come la dico di solito al bar sotto casa, “se tra una battuta e l’altra della batteria passano più di otto secondi, l’orecchio cessa di percepire il suono come “ritmo” ed il cervello registra i suoni come “eventi singoli” e non più facenti parte di un continuum temporale”.
- Iot: questo ci permette in sostanza di decidere il tempo che passa tra la riproduzione di un grano ed il successivo. Ovviamente, giocando con la relazione tra questo parametro ed il precedente (e relative randomizzazioni), possiamo ottenere un suono “continuo” a partire da suoni separati (un ticchettio, per esempio) o, viceversa, “spezzettare” un pad sinfonico in un “treno d’impulsi”.
- Shp e Skw ci consentono di modificare la finestra d’inviluppo, che è qui costituita dai soli tre stadi di attack, sustain e release (il decay in questo caso sarebbe inutile). Shp controlla in percentuale la quantità d’inviluppo dedicata al sustain, mentre Skw decide quanto “bruscamente” debbano cadere attacco e rilascio: in pratica giocando con questi due controlli possiamo modellare la curva di inviluppo, di modo che con Shp settato a 1 e Skw a circa 50% avremo un inviluppo di tipo più o meno gaussiano (la nostra famosa “finestra oscurata”).
- Dlt è un controllo di delay e ci permette di decidere con quanto delay il segnale viene processato
- Feedback ci permette di regolare la quantità di segnale che verrà re-inviato al granularizzatore: agendo – con molta cautela – su questo parametro in relazione a Iot e Dur possiamo “riempire” il suono anche a partire da un singolo “click”.
- Voices è il numero di grani che possono essere riprodotti contemporaneamente, da un minimo di uno fino a 16.
Ora che abbiamo dato un’occhiata all’arsenale a nostra disposizione, possiamo finalmente rompere il ghiaccio e iniziare a provare con qualcosa di concreto. Ho preparato un paio di esempi utilizzando sorgenti audio differenti, per cercare di dare un’idea di base di come la sintesi granulare possa intervenire massicciamente sul segnale al punto da stravolgerlo fino a renderlo mera “sorgente di suono”.
Per il primo esempio, come “mera sorgente” ho scelto un suono che potesse essere riconosciuto al primo istante (un pianoforte solo), riprodotto però in una forma che l’orecchio non fosse in grado di associare immediatamente ad una melodia conosciuta (per non correre il rischio di spostare l’attenzione verso la forma e le note), e che nel contempo non fosse completamente aformale e atonale, per non confondere l’ascolto tra le qualità “destrutturatrici” del sintetizzatore e quelle della composizione originale. La scelta è quindi caduta su “Ludus Tonalis” di Paul Hindemith (il quale attualmente soggiorna in Paradiso, e sta facendo carte false per fare in modo che il Signore mi colpisca fortissimo per quest’onta; scusami Paul). Per limitare i danni ho preso solo i primissimi secondi del Preludio; eccoli qui (chiedo venia agli audiofili per la pessima qualità, ma non avendo sotto mano il disco originale ho dovuto prendere per buono quello che passa youtube):
Nell’esempio che segue, il granularizzatore è impostato per generare grani di ampiezza variabile tra i 30 e i 500 millisecondi, mentre l’intervallo tra un grano e l’altro è “mosso” in modo da passare da un effetto “ritmico” ad uno “continuo”. Anche il numero di voci in gioco viene gradualmente aumentato. L’inviluppo è settato in modo da essere il più “dolce” possibile (fattore “Skw” al massimo e “Shp” al minimo) in modo da alterare il transiente d’attacco dello strumento al fine di renderlo un po’ meno “riconoscibile” all’orecchio, tanto per avere quel margine d’attenzione indispensabile a portare l’ascolto “oltre” il suono originale:
Per “rompere” ancor di più il fronte sonoro, ho aggiunto poi un secondo granularizzatore in modo da avere due “granulator~” che agiscono in parallelo tra loro in modo indipendente. Qui entrano in gioco anche il controllo di pan, il quale viene utilizzato per “separare” i due suoni pur mantenendo un fattore randomico sufficiente a creare un fronte comune nella zona centrale del panorama stereofonico. Uno dei due granularizzatori processa il suono in modo “orizzontale”, addolcendo gli attacchi ed amalgamando il suono con un fattore “Dur” leggermente più ampio e un fattore “Iot” abbastanza basso da non generare discontinuità. Un’altra fonte di possibile “quantizzazione verticale” del suono, ovvero l’armonia, viene “eliminata” randomizzando al massimo il pitch a cui i singoli grani verranno riprodotti. Il secondo granularizzatore agisce in modo opposto, con intervalli ben scanditi tra un grano e l’altro:
Il risultato che possiamo ottenere varia moltissimo – naturalmente – in funzione della sorgente sonora impiegata. Nel caso di un concerto per pianoforte, non possiamo prescindere dalla partitura e sarebbe molto interessante, per esempio, variare i parametri dei vari granularizzatori e il modo in cui sono connessi (niente ci vieta, per esempio, di usarne tre o quattro a cascata invece che in parallelo) in modo correlato alla musica (un passaggio fortissimo sarà processato in un modo, un adagio in un altro etc… etc… anche tenendo conto, magari, del centro tonale e dell’armonia in generale). Questo approccio è molto comune nella musica elettroacustica, dove il dialogo tra suono processato e suono “suonato” costituisce la colonna portante dell’espressività. In questi ambiti, per esempio, è comune utilizzare la sintesi granulare, ad esempio, per rendere “polifonico” uno strumento “monofonico” (ad esempio un fiato come il flauto o il sassofono), giocando con i raddoppi di segnale ed il trasposto di pitch. Per l’appunto, se decidiamo di utilizzare la granularizzazione per “muovere” un segnale statico, possiamo per esempio creare una sorta di “drone granulare” che sfrutti le “connessioni” tra i vari parametri per alterare, ad esempio, il segnale prodotto da un’onda quadra.
Nell’esempio che segue ho impiegato un bel generatore di onda quadra – un Doepfer Dark Energy II – per “foraggiare” una coppia di granularizzatori connessi tra loro: il segnale entra nel primo synth, viene processato ed esce sulla traccia, mentre una sua “copia” viene “deviata” verso un secondo granularizzatore che riceve il segnale dal primo e lo rimanda sulla stessa traccia dopo averci “messo del suo”.
Il segnale originale che andremo a modificare è questo (quanto mi piace la voce del DE…):
E questo è il risultato della sua granularizzazione (ci tengo a precisare, sempre e comunque senza alcun intento di fare “arte” o qualcosa di simile, ma solo ed esclusivamente per dare un’idea, per quanto grossolana, di quel di cui stiamo parlando):
Alla luce di quanto scritto ed ascoltato, possiamo dire di aver dimostrato come da un qualsiasi segnale audio, registrato o meno, concreto o sintetico, tramite la sintesi granulare sia possibile generare paesaggi e suoni totalmente inediti, giocando quindi a saltellare da una parte all’altra di quell’immaginario confine che sta tra “effetto” e “strumento”. Questo non rappresenta una novità; è accaduto spesso nella storia della musica: l’assurgere di quel che era stato pensato come mero “abbellimento” a protagonista indiscusso della traccia. Basti pensare all’uso che molti artisti hanno fatto di macchine anche basilari (per gli standard odierni) quali il delay o il compressore (il reggae nasce sostanzialmente da una errata interpretazione del funzionamento di un delay per chitarra).
Al giorno d’oggi la grainsynth è tornata “di moda” soprattutto grazie alla massiccia diffusione del digitale (e ci credo: sarebbe quantomeno costoso costruire un sintetizzatore granulare completamente analogico, anche se qualche nerd probabilmente saprebbe come fare). Robert Henke (aka Monolake), per esempio, è un grande fan di questa tecnica:
E tutto oro quel che luccica? Come al solito, no. C’è da dire, per esempio, che la natura completamente “digitale” di questa tecnica porta sì a sonorità varie e inconsuete, ma secondo me anche dannatamente piatte: come per tutto quello che viene generato al 100% da un computer, il suono, alla lunga, stanca e “taglia” fastidiosamente in orizzontale – quello che in gergo si chiama “lametta”.
E’ forse una mia personale paranoia, ma credo che in generale gran parte di quello che viene solo “simulato” da un algoritmo, per quanto valido questo algoritmo possa essere, alla fine stia sempre a circa un centinaio di chilometri di distanza da quello che di norma si dovrebbe definire un “buon suono”.
Ecco, l’ho detto… e dopo questa sento già le folle radunarsi in piazza con i forconi e le fiaccole… e la guerra cominciare, per cui mi tocca scappare: chiudo dunque questa mia breve serie sulla sintesi granulare proprio prendendo spunto per quello che potrebbe essere il tema del prossimo articolo: l’annosa diatriba tra “analogico” e “digitale”, in campo audio e musicale. Cosa ne pensate?
Alla prossima!
Tags: Sintesi granulare, tutorial
Trackback from your site.
Comments (2)
Jacopo Mazza
| #
Splendida serie di articoli, grazie di cuore! Piccola domanda, nella lezione 2 hai affermato (parafraso) che due voci è il numero minimo di voci per la sintesi granulare, mentre qui il parametro voices contempla anche la possibilità di una sola voce. Mi chiedevo cosa intendessi per voci nello scorso “episodio”?
Grazie ancora e di nuovo complimenti!
Reply
Enrico Cosimi
| #
dipende dalle decisioni di chi scrive il software. due voci/grani simultanei sono il minimo che alcuni progettisti prevedono per poter eventualmente sovrapporre un grano prima che il precedente sia terminato; un singolo grano è l’impostazione minima che in altre piattaforme viene contemplata per emettere un flusso costante o incostante, ma privo di possibili sovrapposizioni
Reply